데이터마이닝(Data mining) 분석이란?
저번 글 https://ralp0217.tistory.com/20에 이어
데이터 마이닝 분석이란 무엇인가와 데이터 분석에는 어떤 요소들이 있고 전반적인 흐름에 대해서 이론적인 내용
을 쉽게 이해 할 수 있게 리뷰해 보려고 합니다.
아직 데이터마이닝(Data mining)의 개념과 활용 사례를 못 보신 분들은 아래 링크를 참고해 주세요.
데이터 마이닝의 개념과 활용 사례
데이터 마이닝이란 무엇일까를 쉽게 설명해 보는 시간을 가지려 합니다. 이 글을 끝까지 보시면 데이터 마이닝의 개념에 대해서 확실히 알고, 왜 필요한 기술하고 방법 알 수 있을 겁니다. 추가�
ralp0217.tistory.com
데이터 마이닝은 주로 Multivariate data(다변량 데이터)를 분석할 때 쓰이곤 합니다.
Multivariate data라고 하면 생소하게 들릴 수 있지만 우리가 흔히 알고 있는 테이블(행렬 구조 데이터)를 생각하면 됩니다. 즉 다변량: 변수 개수가 여러개인 데이터 들입니다.
예를 들면 아래와 같은 여러개의 숫자값, 시그널, 네트워크, 이미지(영상) 등 모두 다변량 데이터라고 할 수 있습니다.
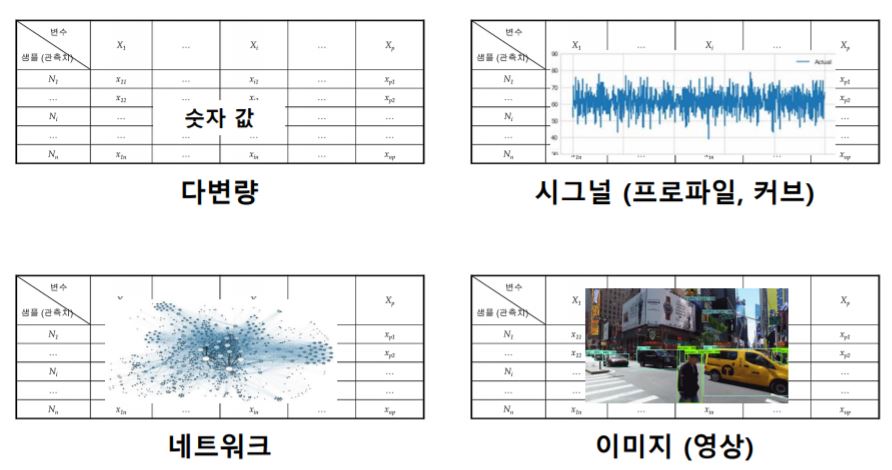
좀더 와 닿는 예를 들면, 코로나 확진자 그래프를 많이 보시곤 하시죠?
전국 코로나 확진자 데이터를 보면 대구, 서울, 경기...으로 각각의 표,그래프가 있습니다.
그런 것들이 다변량 데이터(Multivariate data)라고 생각하시면 됩니다.
그러면 데이터들이 어떻게 생겼나에 대해서 자세히 들여다 보면, 다음과 같은 인과 관계를 알 수 있습니다.
*데이터 구조(인과 관계)
ex. 코로나확진자수 데이터=> X(서울,경기)-> Y(66명,30명)
(X는 Independent variable(독립 변수), Explanatory variable(예측 변수), Input variable(인풋 변수)라고도 하며,
Y는 Dependent variable(종속 변수), Response variable(반응 변수), Output variable(아웃풋 변수)라고도 불립니다.)
X->Y라고 하면 그 사이에 어떤 모델(함수)가 x라는 INPUT이 들어왔을 떄 y를 출력하는 기능을 하고 있다는 것을 유추할 수 있겠죠? 그 함수가 바로 데이터 마이닝을 하게 해주는 모델(F)인 것입니다. 추가적으로 데이터 마이닝 분석을 이해하기 위해서는 모델(machine learning model)에 대해서 이해가 필요합니다. 따라서 머신러닝 모델의 대략적인 개념을 훑어보도록 하겠습니다.
다시 데이터 구조를 살펴보면,
데이터는 Training data와 Test data로 나눠서 사용합니다.
Training data는 학습 모델(F)를 구축할 때, 즉 훈련시킬 때 사용하고, 그 구축된 모델(F)를 가져와서 테스트 시에 사용합니다.
즉, Training phase는 얼마나 잘 학습이 되었는가 '적합 수준'을 체킹하고, Test phase에서는 예측이 실제 정확한가 '예측 성능 수준'을 체킹해서 모델링을 마치면 최종 결과를 나타냅니다.
무엇을 예측할 것인가? 데이터로 무엇을 할 것이냐에 따라서 데이터 마이닝 기법이 달라지는데 대표적으로 다음 3가지로 분류 할 수 있습니다.
-Clustering -> 그룹화 한다는 것입니다. 예를 들면 한 집단에서 키 180cm이상 그룹과 180cm이하 이룹을 나누는 것을 clustering이라고 합니다. 그 때는 이 방법을 씁니다.
-Inference -> 연관성을 찾는 것입니다. 예를 들면 코로나가 제일 많이 발생한 지역(장소)를 보고 고위험시설을 찾는 것이라고 이해하시면 됩니다.
-Prediction-> 예측입니다. Input데이터들을 보고 output을 추정하는 것입니다. 예를 들면, 50일동안 코로나 확진자수를 보고 내일 코로나를 예측해보는 것입니다.
연습문제 - Example : '월급'은 나이, 년도, 교육 수준에 영향을 받는다.
'월급' = Y, 나이,년도,교육 수준 : X
1. X와 Y사이에서 관계에서 연관성있는 X요소는 어떤 것일까요?? 이 문제를 어떤 분류에 속할 까요??
정답은 Inference분류에 속합니다.
2. X요소들을 이용해 Y를 예측하는 모델을 만드려면 무슨 방법을 써야 할까요??
정답은 Prediction( regression)분류를 사용해야 합니다.
Prediction(예측)에 대해서 좀 더 자세히 살펴보겠습니다.
Prediction(예측)에는 2가지로 세분화 할 수 있습니다.
Classification(범주 예측/구분)과 Regression(수치 예측)으로 구분할 수 있습니다.
Classifiaction의 예로는 필기체(숫자) 모양을 보고 데이터에 있는 0,1,2,3,4,5,6,7,8,9중에 어느 숫자에 가까운 지 예측하는 것입니다. (cf.MNIST예제)

Regression의 예로는 교육수준이 어느 정도인 사람들을 보고 월급이 어느 정도일까(수치)를 예측 해보는 것이 될 수 있게습니다.
이 classification과 regression은 또, Supervised Learning(지도 학습)이라고 합니다.
즉 지도학습이란 학습데이터로부터 X->Y의 관계를 설명하는 함수(F)를 찾는 방법론을 말하는데,
쉽게 말하면 X->Y관계식에서 Y가 있으면 지도학습이고 Y없이 X가지고 관계를 찾는 학습방식은 비지도 학습이라고 불립니다.
+Classification(분류)과 Regression(회귀)의 비교

+학습모델 구축 시, 문제 상황(Task) 별 분류 유형
머신러닝 에는 다음과 같은 학습 모델 구축 방법이 있습니다.
1. 지도학습 (Classification, Regression)
2. 비지도학습 ( Clustering)
3. 강화학습 (Markov Decision Process, DQN, Policy Gradient)
4. 준지도학습 ( Transductive, Inductive)
자세한 머신러닝(딥러닝)에 대해서 궁금하신 분들은 이전 글 https://ralp0217.tistory.com/5을 참고해 주세요~
딥러닝(Deep Learning) 이란?
인공지능을 공부하며 딥러닝의 개념에 대해서 정확한 이해를 위해 다시 한 번 정리해보는 시간을 가져보려 한다. 최근 들어 인공지능이라는 말과 머신러닝, 딥러닝이라는 말은 거의 같은 의미��
ralp0217.tistory.com
다음 글에서는 실질적인 데이터 마이닝 분석 알고리즘에 대해서 다뤄보겠습니다.
'AI 기술 정리 > 빅데이터&데이터마이닝' 카테고리의 다른 글
| MMDS(mining massive data sets)와 분산 파일 시스템(Distributed File System) (6) | 2020.09.26 |
|---|---|
| 데이터 마이닝 분석 프로세스란? (11) | 2020.09.22 |
| 데이터 마이닝의 개념과 활용 사례 (4) | 2020.09.08 |



댓글