MMDS(mining massive data sets)와 분산 파일 시스템(Distributed File System)

데이터는 가치와 지식을 지니고 있지만, 그러한 가치와 지식을 추출해 내기 위해서는 다음의 것들이 필요하다.
1. 데이터들을 저장할 소프트웨어 저장소(Systems)
2. 데이터들을 관리할 수 있는 Databases
3. 그리고 이 것들을 분석할 수 있는 기능/기술(data mining)
Data mining은 very large datasets에서 actionable한 information(실행하는 한 정보)을 추출하는 것이다.
데이터마이닝(Data mining) 분석이란?
데이터마이닝(Data mining) 분석이란? 저번 글 https://ralp0217.tistory.com/20에 이어 데이터 마이닝 분석이란 무엇인가와 데이터 분석에는 어떤 요소들이 있고 전반적인 흐름에 대해서 이론적인 내용 을
ralp0217.tistory.com
데이터 마이닝은 단순한 머신러닝은 아니지만 어느 부분은 맞다.
scale한 알고리즘을 다룬다(즉, 데이터의 크기가 커지거나 작아도 잘 작동하는 알고리즘)
따라서, Parallelization(병렬화) 은 필수적이다.
데이터 마이닝은 하는 방법은 크게 두가지가 있다.
1. Descriptive methods(기술적인 방법) :
-Clustering(군집화)과 같이 human-interpretable patterns(인간이 이해할 수 있는 패턴)을 찾는데에 중점을 둔다.
(clustering은 동물사진들의 데이터를 쭉 나열했을 때 새들과 포유류로 구분진어 분류한 것들이 클러스트링의 예이다)
2. Predictive methods(예측 방법) : 여러 인자들을 사용해서 미래의 값을 예측하는 것. 예를 들면 유투브에서 유저의 과거 영상 재상 목록을 보고 추천해주는 시스템
데이터 마이닝은 머신러닝, 통계학, 인공 지능, 데이터 베이스의 약간씩 겹치는 부분들이 있는데, 주요 특징을 정리해보면,
Scalability(big data): 커지거나 작아지더라도 수용
Algorithm
Computing architectures(처리 구조)
large data
이 4가지 항목에 중점을 둔다.
그러면 알아봐야 할 게, 다른 종류의 데이터 타입일 떄 high dimensional이거나, graph형태이거나 infinite/never-ending, labeled되어 있을 때 어떻게 다른 모델로 계산을 수행할 것인지 알아봐야 한다. Computation하는 유형에는 MapReduce, Streams and online algorithm, Single machine in-memory 등이 있다.
기법들을 정리해보면 다음과 같다.

이런 것들을 배우면, 현실 세계에서 문제를 어떻게 해결할 수 있는지 보면,
예) Recommender systems, Market Basket Analysis(장바구니 분석), Spam detection, Duplicate document detection(중복 문서 감지) 등을 해결할 수있고, Linear algebra(선형 대수학)에 관련된 시스템, Optimization, Dynamic programming, Hashing에 기반한 도구들에 대해 알아봐야 한다.
데이터 마이닝을 위해 대규모 연산 작업을 할 때 문제가 되는 것은?
1. 연산 작업을 어떻게 분배할 것인가
2. 분산 프로그램을 어떻게 쉽게 작성할 것인가
컴퓨터들이 망가진다.( 한 컴퓨터가 1000일을 버틴다고 가져하면, 내가 만약 1000대의 컴퓨터(서버)를 사용할 경우, 하루에 한 대씩 망가진다)
따라서 대규모 연산 작업을 수행할 때는 알아서 작업을 잘 분산시켜 줘야 하고, 코딩하기도 쉬워야 하며, 일부 기계가 망가져도 잘 동작하는 시스템이 필요하다.
그리고 네트워크를 통해 데이터를 주고 받으면 시간이 굉장히 오래걸린다라는 점이있다.
-> 컴퓨터 구조를 보면 데이터를 읽어 올때, CPU안의 Register가 가장 빠르고, 그 다음이 Cache memory, 그 다음 main memory, 그 다음이 Disk가 되어서 가급적이면 disk를 읽지 말아야 프로그램이 빨리 동작하는데 분산시스템에서도 비슷하게 네트워크를 통해서 데이터를 많이 주고 받으면 좋지 않다.
그래서 생각해낸 것이 계산이 필요할 때 계산을 수행하는 컴퓨터에 데이터를 주지 말고 거꾸로 데이터를 갖고 있는 컴퓨터에 데이터를 갖고 있는 컴퓨터에 계산(Computation)을 주자.(역발산)
(예를 들면 100GB짜리 텍스트를 여러대의 컴퓨터에 분산되어 저장되어 있다고 가정하면, masterPC에서 이 여러대의 컴퓨터에 데이터를 네트워크를 통해서 받아와서 연산을 수행하려면 시간이 굉장히 오래걸리므로 이렇게 할 것이 아니라, 마스터가 파일이 저장되어 있는 PC들에게 단어의 연산을 수행하라고 명령만 내린다. 그러면 각 PC들은 병렬적으로 연산을 수행한 다음 그결과를 Master에게 보내준다. 그러면 master는 연산 결과를 합치기만 하면 된다.)
정리하면 큰 데이터를 주고 받는 데에는 시간이 많이 걸리니까, 명령과 결과만 주고 받자는 식이다. 또한 reliability(안정성)를 위해 동일한 파일을 여러 곳에 분산하여 저장해야 한다.
그래서 Spark와 Hadoop은 이러한 문제를 해결한다.
Reliability에 대해서 좀 자세히 알아보면, 일부의 데이터들이 손상되었을 때 어떻게 손실없이 데이터의 무결성을 유지할 수 있을까 하면, 그 해답은 Distributed File System(분산 파일 시스템)에서 찾을 수 있다.
분산파일 시스템은 100GB~TB까지 커버가 가능하고 업데이트는 빈번하지 않지만 파일을 읽고 추가되는 일이 빈번할 때 적합하다.(그러나 항공권 예약 시스템에서 사용되는 데이터는 크기가 매우 크긴 하지만, 자주 갱신되는 문제가 있기 때문에 이 파일 시스템을 사용하는데에는 적합하지 않다)
Distributed File System(분산 파일 시스템) 구성 요소
Distributed File System(분산 파일 시스템)에는 Chunk servers와 Master node로 구성되어 있다.
(예) 100GB짜리 데이터는 Chunk(덩어리)라는 단위로 쪼개져서 분리하게 된다)
Chunk의 크기는 16~64MB정도
Each chunk replicated (청크에 있는 데이터들이 망가질 수 있기 떄문에 2번에서 3번정도 복제되어 데이터 보관)
복제본들은 독립적인 racks(컴퓨터 묶음 위치나 보관소같은거) 에 보관.
master node는 각 파일들이 저장되어 있는 위치에 대한 metadata(파일 저장하고 있는 chunk주소록)들을 가지고 있다.
이 또한 복제되어 있다.
파일 접근 순서를 따져보면, 먼저 마스터 노드에게 파일을 가지고 있는 청크서버를 찾으라고 하고, 데이터의 접근할 수있는 청크 서버에 데이터를 달라고 요청해서 데이터를 받아오는 것이다.
분산 파일 시스템은 Chunk들을 여러 기기에 분산시키고 그와 동시에 동일한 Chunk를 여러개 복사해서 서로 다른 기기에 저장한다 . 그래서 디스크나 기기가 갑자기 망가졌을 때에도 recovery(복구)를 수행할 수가 있게 된다
(chunk서버는 데이터를 저장하기도 하지만 계산(computation)을 담당하기도 한다)
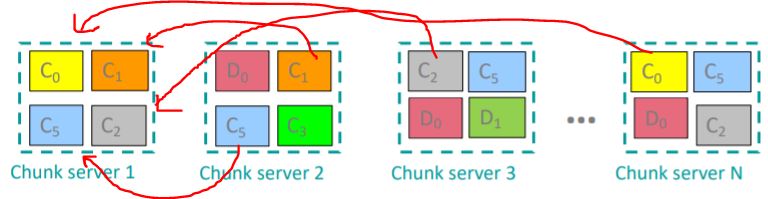
--> 청크서버 1번이 망가졌다고 하면, 2,3,4에서 복제된 데이터를 가지고 복사해와서 청크 서버1을 복구할 수 있게 된다.
'AI 기술 정리 > 빅데이터&데이터마이닝' 카테고리의 다른 글
| 데이터 마이닝 분석 프로세스란? (11) | 2020.09.22 |
|---|---|
| 데이터마이닝(Data mining) 분석이란? (14) | 2020.09.14 |
| 데이터 마이닝의 개념과 활용 사례 (4) | 2020.09.08 |



댓글